

Google a découvert – Actuellement non indexé – Qualité, timing ou vitesse du serveur
Martin Splitt, de Google, a publié une vidéo dans sa série SEO Made Easy sur le thème de la note d'état du rapport d'indexation des pages « Découvertes – Actuellement non indexées » de la Search Console de Google. En bref, il y a trois raisons principales pour lesquelles vous verrez des pages dans cette catégorie :
(1) Problèmes de qualité avec ces pages
(2) Votre serveur est lent pour Googlebot
(3) Google a simplement besoin de plus de temps pour indexer ces pages (ce qui peut être lié au point 2 ci-dessus).
Concernant la qualité, Martin Splitt a déclaré : « Lorsque Google Search détecte une tendance à la qualité médiocre ou à un contenu peu riche sur certaines pages, celles-ci peuvent être supprimées de l'index et rester dans la liste des pages découvertes. » « Googlebot connaît ces pages mais choisit de ne pas les traiter », car elles ne sont pas de qualité suffisante, a-t-il expliqué. Il a ajouté : « Si Google Search détecte une tendance dans les URL au contenu de mauvaise qualité sur votre site, il peut ignorer complètement ces URL et les laisser également dans la liste des pages découvertes. »
Que pouvez-vous faire ? « Si vous vous souciez de ces pages, vous devriez peut-être retravailler le contenu pour qu'il soit de meilleure qualité et vous assurer que vos liens internes relient ce contenu à d'autres parties de votre contenu existant », a-t-il déclaré. Assurez-vous donc d'examiner le contenu et de l'améliorer, mais voyez également vers quelles pages vous pouvez lier ce contenu à partir d'autres pages déjà indexées.
Pour être clair, la documentation d'aide de Google pour les éléments découverts – actuellement non indexés ne mentionne en réalité que les problèmes de serveur. Elle se lit comme suit :
La page a été trouvée par Google, mais n'a pas encore été explorée. En règle générale, Google souhaitait explorer l'URL, mais cela devait surcharger le site. Google a donc reprogrammé l'exploration. C'est pourquoi la date de la dernière exploration est vide dans le rapport.
Mais comme nous l'avons déjà évoqué en 2018, nous savons que cela concerne également les problèmes de qualité. Ce n'est donc pas nouveau, mais c'est bien d'avoir une vidéo sur ce sujet.
Voici la vidéo :
Voici une capture d'écran de ce rapport d'indexation de page avec le champ « Découvert – Actuellement non indexé » pour ce site :
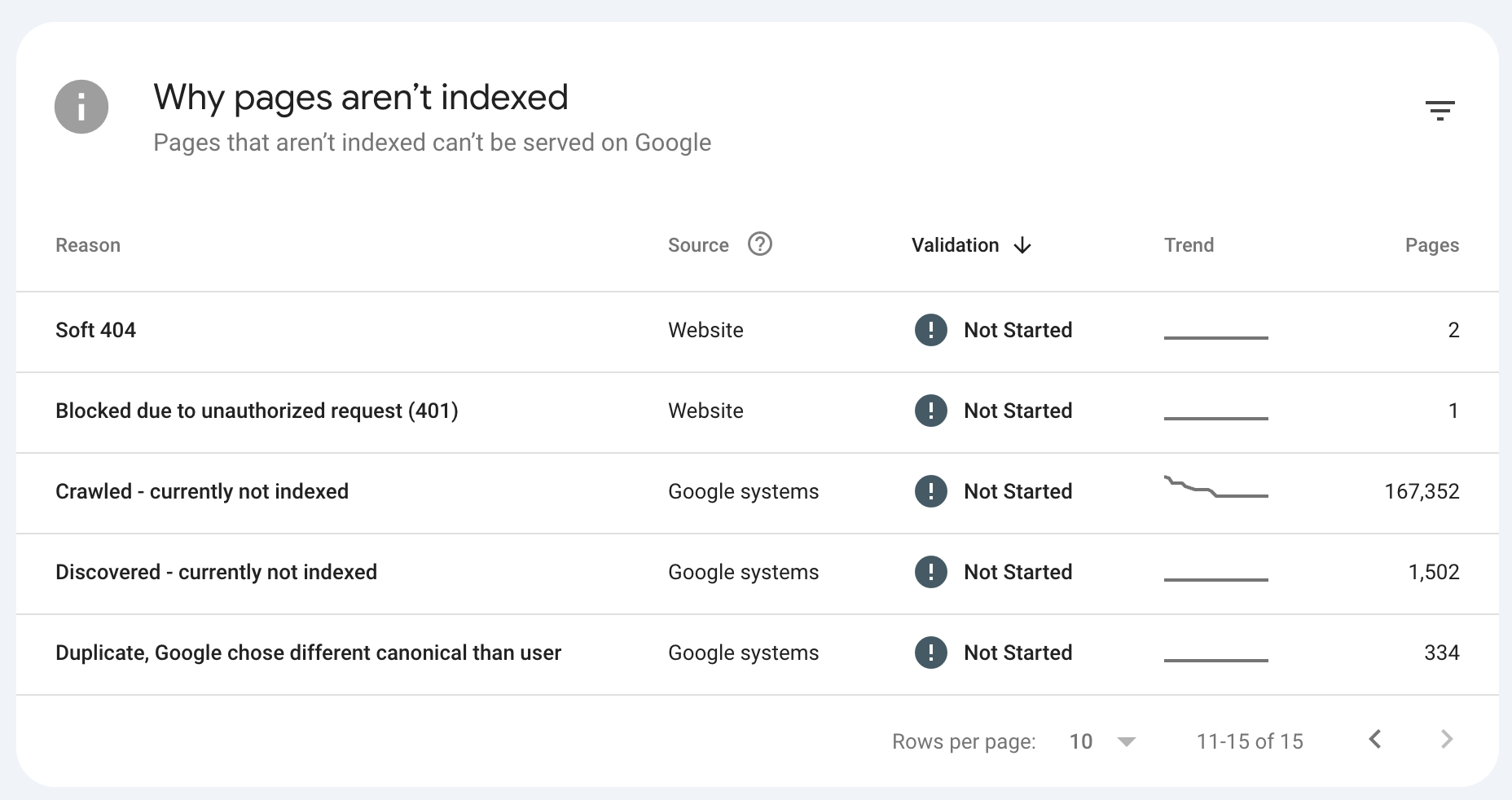
Voici la transcription :
Vidéo Google sur Discovered – Actuellement non indexée
Aujourd'hui, nous allons nous pencher sur le statut « Découvert – actuellement non indexé » de Google Search Console dans le rapport d'indexation des pages.
Lorsque vous utilisez Google Search Console, et vous devriez l'utiliser, vous avez probablement consulté le rapport d'indexation des pages et vous avez peut-être vu ce genre de raisons pour lesquelles les pages ne sont pas indexées. L'une des questions les plus fréquentes que nous recevons à ce sujet est le statut découvert comme non indexé actuellement. Voyons ce que cela signifie et ce que vous pouvez faire à ce sujet.
Tout d'abord, Google n'indexe presque jamais tout le contenu d'un site. Il ne s'agit pas d'une erreur ni même nécessairement d'un problème à résoudre. Il s'agit d'une note sur le statut des pages mentionnées ici. Pour comprendre ce que cela signifie, nous devons examiner la manière dont une page évolue dans les systèmes et processus qui composent la recherche Google.
Au tout début, Googlebot trouve une URL quelque part qui peut être un plan de site ou un lien par exemple. Googlebot a maintenant découvert que cette URL existe. Googlebot l'inscrit essentiellement dans une liste de tâches à effectuer d'URL à visiter et éventuellement à indexer plus tard. Dans un monde idéal, Googlebot se mettrait immédiatement au travail sur cette URL, mais comme vous le savez probablement grâce à votre propre liste de tâches, ce n'est pas toujours possible. Et c'est la première raison pour laquelle vous pouvez voir cela dans Google Search Console. Googlebot n'a tout simplement pas encore réussi à explorer l'URL car il était occupé avec d'autres URL. Parfois, il suffit donc d'un peu plus de patience de votre part pour obtenir ce résultat. Finalement, Googlebot peut l'explorer. C'est le moment où il récupère la page sur votre serveur et la traite plus avant pour éventuellement l'indexer. Une fois qu'il commence à explorer, l'URL passe à la page actuellement non indexée ou la page est indexée.
Mais que se passe-t-il si le contenu n'est pas exploré et reste dans la catégorie découverte et non indexée ? En général, cela est lié à votre serveur ou à la qualité de votre site Web.
Commençons par examiner les raisons techniques potentielles. Imaginons que vous possédez une boutique en ligne et que vous venez d'ajouter 1 000 nouveaux produits. Googlebot découvre tous ces produits en même temps et souhaite les explorer. Cependant, lors des explorations précédentes, il a remarqué que votre serveur devenait très lent, voire surchargé, lorsqu'il essayait d'explorer plus de 10 produits en même temps. Il veut éviter de surcharger votre serveur. S'il décide d'explorer, il peut le faire sur une période plus longue, par exemple 10 produits à la fois sur quelques heures, plutôt que tous les mille produits dans la même heure. Cela signifie que les 1 000 produits ne sont pas tous explorés en même temps. Googlebot mettra alors plus de temps à parcourir ces produits.
Il est judicieux de consulter le rapport de statistiques d'exploration et la section de réponse pour voir si votre serveur répond lentement ou avec des erreurs HTTP 500 lorsque Googlebot tente d'explorer. Notez que cela n'a généralement d'importance que pour les sites comportant de très grandes quantités de pages, disons des millions ou plus, mais des problèmes de serveur peuvent également survenir avec des sites plus petits. Il est judicieux de vérifier auprès de votre hébergeur ce qu'il faut faire pour résoudre ces problèmes de performances s'ils surviennent.
L'autre raison, beaucoup plus courante, pour laquelle les pages restent dans la catégorie Découverte et ne sont pas indexées est la qualité. Lorsque Google Search détecte une tendance à la qualité médiocre ou à un contenu léger sur certaines pages, celles-ci peuvent être supprimées de l'index et rester dans la catégorie Découverte. Googlebot connaît ces pages, mais choisit de ne pas les traiter. Si Google Search détecte une tendance dans les URL contenant du contenu de mauvaise qualité sur votre site, il peut ignorer complètement ces URL et les laisser également dans la catégorie Découverte.
Si vous tenez à ces pages, vous souhaiterez peut-être retravailler le contenu pour qu'il soit de meilleure qualité et vous assurer que vos liens internes relient ce contenu à d'autres parties de votre contenu existant. Consultez notre épisode sur les liens internes pour plus d'informations à ce sujet.
En résumé, certains sites auront des pages qui ne seront pas indexées et ce n'est généralement pas un problème. Si vous pensez qu'une page doit être indexée, vous devriez envisager de vérifier la qualité du contenu de ces pages qui restent découvertes et qui ne sont actuellement pas indexées. Assurez-vous également que votre serveur n'envoie pas de signaux à Googlebot indiquant qu'il est surchargé lorsqu'il explore.
Discussion sur le forum X.