

Google : les URL exclues par Robots.txt ne sont pas supprimées tant que les URL ne sont pas retraitées individuellement
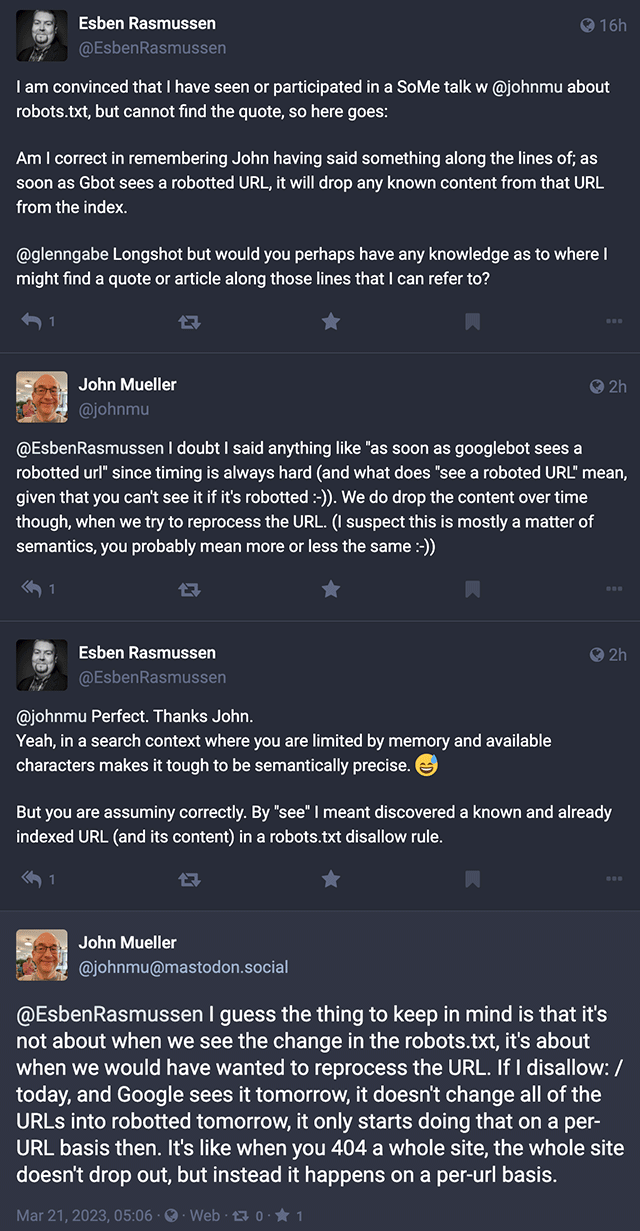
John Mueller de Google a publié une clarification sur la manière et le moment où Google traite les demandes de suppression ou les demandes d’exclusion que vous faites dans votre fichier robots.txt. L’action n’est pas prise lorsque Google découvre le changement dans votre fichier robots.txt, mais plutôt après que le fichier robots.txt a d’abord été traité, puis que les URL spécifiques concernées sont retraitées individuellement par la recherche Google.
Les deux doivent arriver. Tout d’abord, Google doit prendre en compte vos modifications dans votre robots.tx, puis Google doit retraiter les URL individuelles, URL par URL, pour que toute modification de la recherche Google se produise. Cela peut être rapide ou non, selon la rapidité avec laquelle les URL spécifiques sont retraitées par Google.
John Mueller a posté ceci sur Mastodonte en disant, « la chose à garder à l’esprit est qu’il ne s’agit pas de savoir quand nous voyons le changement dans le robots.txt, il s’agit du moment où nous aurions voulu retraiter l’URL. Si j’interdis : / aujourd’hui, et que Google le voit demain, il ne change pas toutes les URL en robotisé demain, il ne commence alors à le faire que par URL. C’est comme lorsque vous 404 un site entier, l’ensemble du site n’abandonne pas, mais à la place cela se produit sur un base par URL. »
Voici une capture d’écran de cette conversation, juste pour que vous ayez le contexte :
En fait, de nombreux algorithmes de classement fonctionnent de cette façon, c’est pourquoi lorsqu’une mise à jour est déployée, il faut parfois environ deux semaines pour qu’elle soit entièrement déployée, car c’est le temps que prennent les URL les plus importantes sur Internet pour que Google les retraite. Certaines URL sur Internet peuvent prendre des mois pour être retraitées, à titre informatif.
Forum de discussion sur Twitter.