

Les données structurées n'aident pas à la visibilité dans la recherche d'IA
Il y a beaucoup de gens dans la communauté disant que la mise en œuvre de données / schémas structurés sur vos pages vous aidera avec la visibilité de la recherche d'IA. Mais peu l'ont vraiment testé jusqu'à présent. Et ces quelques tests montrent que l'ajout de données / schéma structurés n'aide pas avec votre visibilité dans la recherche d'IA, du moins pas encore.
Le premier à tester cela a été Mark Williams Cook qui a publié sur LinkedIn une expérience qu'il a menée où il a publié une « explication visuelle de la raison pour laquelle votre LLM préféré n'utilise pas de schéma dans leurs données de formation principale ». Il a expliqué comment lorsque les LLMs traitent la page, il « détruit » le balisage du schéma et ne l'utilise donc pas.
Il a écrit:
Les LLM fonctionnent par contenu « tokenising ». Cela signifie prendre des séquences communes de caractères trouvées dans le texte et la frappe d'un « jeton » unique pour cet ensemble. Le LLM prend ensuite des milliards d'échantillons « fenêtres » d'ensembles de ces jetons pour créer une prédiction sur ce qui vient ensuite.
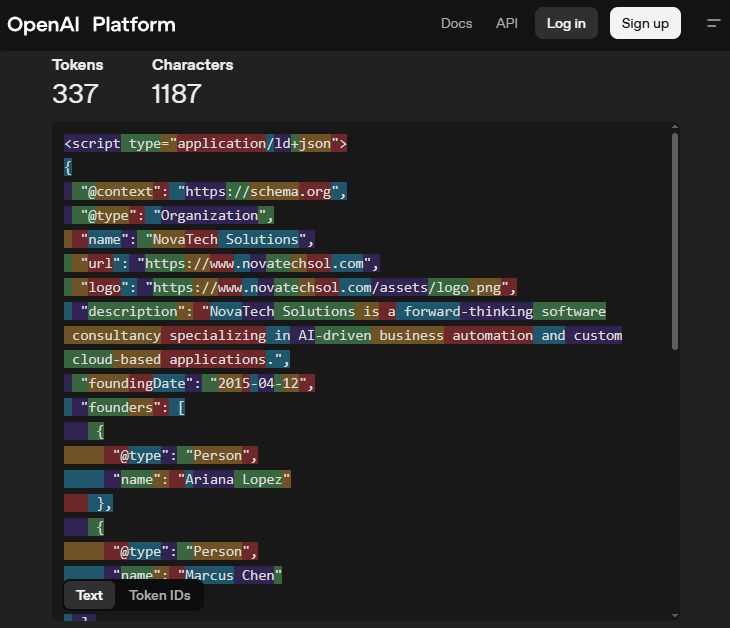
L'image ci-dessous est un exemple de schéma qui a un changement de couleur appliqué qui représente cet ensemble de caractères est un jeton unique comme le modèle GPT-4O.
Ce que vous remarquerez, c'est que le schéma est « détruit ». Par exemple, le schéma « @type »: « organisation », est décomposé, il existe donc des jetons séparés pour « type » et « organisation », ce qui signifie qu'en termes de tokénisation, les mots réguliers « type » et « organisation » ne se distinguent pas du schéma.
Si le schéma était inclus dans ces données de formation, tout ce qu'il ferait en réalité est de dire qu'il existe une probabilité légèrement (probablement insignifiante) de jetons tels que « @ apparaissant avant le mot » contenu « .
Voici sa capture d'écran:
Si ce n'est pas assez bon pour vous, Julio C. Guevara l'a également testé et écrit sur son test sur LinkedIn également. Il a déclaré « Nous avons mis en place deux pages de produits du même produit inventé que Gemini et Chatgpt n'avaient jamais vu auparavant. Une page avait tout le contenu visible dans le HTML en tant que texte + données structurées, l'autre page n'avait que des données structurées et d'autre rien de visible comme texte (visuellement vide). »
Le résultat ne montre aucun avantage. Il a écrit: « Nous avons essayé différentes invites d'extraction, des centaines de fois, pour voir si les LLM pouvaient redonner des informations comme le prix, les couleurs, les numéros de SKU. Surprise, surprise: cela n'a fonctionné que sur la page avec des informations visibles comme texte. »
Son test montre que les LLM ne pouvaient même pas voir le texte dans les données structurées.
Bien sûr, tout cela peut changer à l'avenir, mais voici quelques tests précoces effectués à ce sujet.
Discussion du forum sur LinkedIn.