

Les documents juridiques d'appel au monopole de la recherche Google mentionnent les signaux de recherche
Comme vous le savez, Google a fait appel de sa décision relative au monopole de la recherche et a ainsi déposé un certain nombre de nouveaux documents auprès du tribunal. L'un est un affidavit d'Elizabeth Reid, vice-présidente et responsable de la recherche de Google. L'autre est celui de Jesse Adkins, directeur de la gestion des produits pour la syndication des recherches et la syndication des annonces de recherche.
Dans l'affidavit d'Elizabeth Reid — document n° 1471, pièce jointe n° 2, Reid explique pourquoi Google pense qu'il ne devrait pas donner suite à certains des recours du tribunal.
Plus précisément, Google ne souhaite pas aller jusqu'au bout des « Divulgations requises des données » et de la section V intitulée « Syndication requise des résultats de recherche ». Pourquoi? Reid a écrit : « Google subira un préjudice immédiat et irréparable en raison du transfert de ces informations exclusives aux concurrents de Google, et pourrait en outre subir un préjudice financier et de réputation irréparable si les données fournies aux concurrents étaient divulguées ou piratées. »
Les détails que Google devrait fournir à ses concurrents incluent :
- un identifiant unique (« DocID ») de chaque document (c'est-à-dire, URL) dans l'index de recherche sur le Web de Google et des informations suffisantes pour identifier les doublons ;
- « un mappage DocID vers URL » ; et
- « pour chaque ID de document, l'heure (A) à laquelle l'URL a été vue pour la première fois, (B) l'heure à laquelle l'URL a été explorée pour la dernière fois, (C) le score de spam et (D) l'indicateur de type d'appareil. »
Google pense que la remise de cela :
(1) Donner un avantage injuste à ses concurrents car Google a passé des dizaines d’années à travailler sur ces méthodes.
(2) Cela révélerait les URL que Google considère comme plus importantes que d’autres.
(3) Cela permettrait aux spammeurs de procéder à l’ingénierie inverse de certains de ses algorithmes.
(4) Il mettra les informations privées des chercheurs à la disposition de ses concurrents.
Google a écrit :
Premièrement, la technologie d'exploration de Google traite les pages Web sur le Web ouvert, en s'appuyant sur des signaux propriétaires de qualité et de fraîcheur des pages pour se concentrer sur les pages Web les plus susceptibles de répondre aux besoins d'information des utilisateurs. Deuxièmement, Google balise les pages Web explorées avec des annotations propriétaires de compréhension de page, y compris des signaux permettant d'identifier le spam et les pages en double. Enfin, Google crée l'index à l'aide des pages Web balisées générées lors de la phase d'annotation. L'index de Google utilise une structure hiérarchique propriétaire qui organise les pages Web en fonction de la fréquence à laquelle Google s'attend à ce que le contenu soit consulté et de la fraîcheur du contenu (plus le contenu doit être récent, plus Google doit explorer la page Web fréquemment).
Il continue ainsi : « L'image ci-dessous du démonstratif (RDXD-28.005) montre la fraction de pages (en vert) qui figurent dans l'index Web de Google, par rapport aux pages explorées par Google (en rouge). En vertu du jugement final, Google doit divulguer aux concurrents qualifiés le sous-ensemble organisé reflété en vert. »
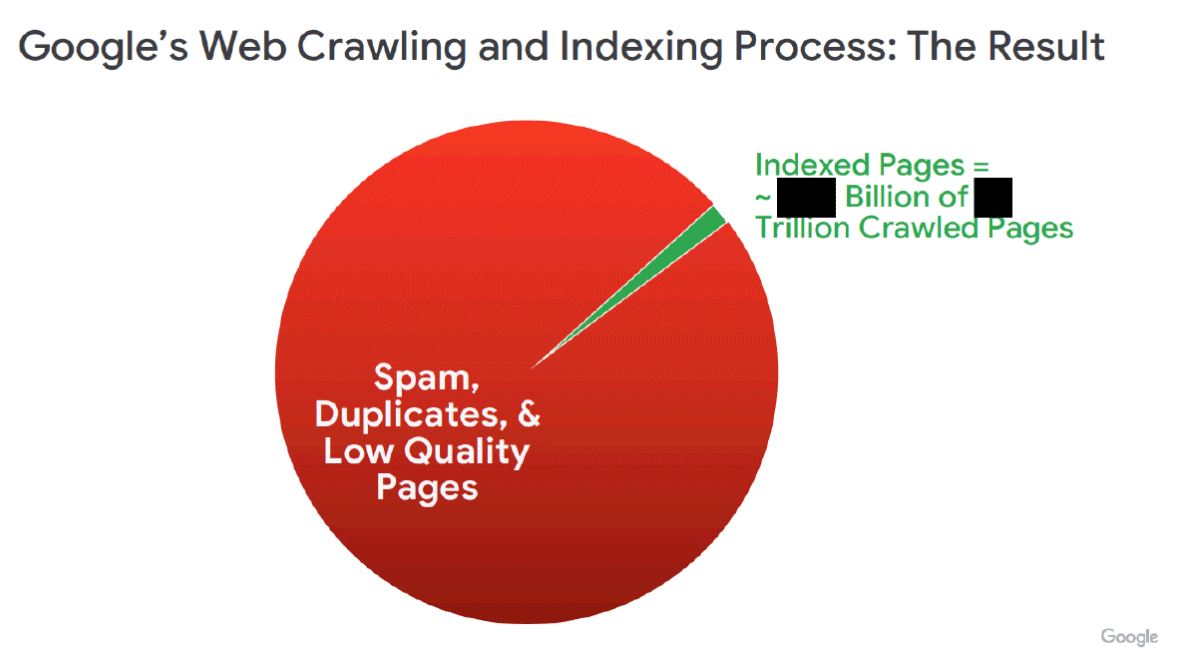
Oui, cela montre combien d'URL Google connaît sur ce qui est indexé par Google. C'est une énorme différence !
Google a ajouté :
Si des spammeurs ou d'autres acteurs malveillants devaient accéder aux scores de spam de Google auprès de concurrents qualifiés via des fuites ou des violations de données (un résultat réaliste étant donné l'énorme valeur des données), la qualité de la recherche de Google serait dégradée et ses utilisateurs exposés à une augmentation du spam, affaiblissant ainsi la réputation de Google en tant que moteur de recherche digne de confiance.
La divulgation des valeurs du signal de spam pour les pages Web indexées de Google via une fuite ou une violation de données dégraderait la qualité de la recherche de Google et diminuerait la capacité de Google à détecter le spam. Comme je l’ai déclaré lors de l’audience sur les recours, le Web ouvert est rempli de spam. Google a développé de nombreuses technologies de lutte contre le spam pour tenter de garder le spam hors de l'index. La lutte contre le spam dépend de l'obscurité, car la connaissance externe des mécanismes ou signaux de lutte contre le spam élimine la valeur de ces mécanismes et signaux.
Si des spammeurs ou d'autres acteurs malveillants avaient accès aux scores de spam de Google, ils pourraient contourner les technologies de détection de spam de Google et paralyser Google dans ses efforts de lutte contre le spam. Par exemple, les spammeurs achètent ou piratent généralement des sites Web légitimes et remplacent le contenu par du spam, une attaque rendue plus facile si les spammeurs peuvent utiliser les scores de spam de Google pour cibler des pages Web que Google a évaluées comme présentant un faible risque de spam. De cette manière, les divulgations forcées sont susceptibles de provoquer davantage de spam et de contenu trompeur en réponse aux requêtes des utilisateurs, compromettant ainsi la sécurité des utilisateurs et sapant la réputation de Google en tant que moteur de recherche digne de confiance.
Ensuite, il entre dans GLUE et RankEmbed :
Données côté utilisateur utilisées pour construire, créer ou exploiter le(s) modèle(s) statistique(s) GLUE » et (ii) « Données côté utilisateur utilisées pour former, créer ou exploiter le(s) modèle(s) RankEmbed », « à un coût marginal ».
Les « données côté utilisateur » couvertes par la section IV.B du jugement final comprennent des données utilisateur hautement sensibles, y compris, mais sans s'y limiter, la requête de l'utilisateur, son emplacement, l'heure de la recherche et la manière dont l'utilisateur a interagi avec ce qui lui a été affiché, par exemple les survols et les clics.
Les données utilisées pour construire le modèle « Glue » de Google incluent également tous les résultats Web renvoyés et leur ordre, ainsi que toutes les fonctionnalités de recherche renvoyées et leur ordre. Le modèle Glue capture ces données pour les treize mois précédents de journaux de recherche.
Vous pouvez également consulter l'affidavit de Jesse Adkins — document n° 1471, pièce jointe n° 3 — qui se trouve du côté de l'annonce.
Discussion sur les forums privés de Marie Haynes (désolé).